

In this blog entry, I shall highlight one important, yet a less known, feature of the option keep() in nested regression tables of asdoc. If you have not used asdoc previously, this half-page introduction will put you on a fast track. And for a quick start of regression tables with asdoc, you can also watch this YouTube video.
Option keep()
There are almost a dozen options in controlling the output of a regression table in asdoc. One of them is the option keep(list of variable names). This option is primarily used for reporting coefficient of the desired variables. However, this option can also be used for changing the order of the variables in the output table. I explore these with relevant examples below.
1. Changing the order of variables
Suppose we want to report our regression variables in a specific order, we shall use option keep() and list the variable names in the desired order inside the brackets of option keep(). It is important to note that we have to list all variables which we want to report as omitting any variable from the list will cause asdoc to omit that variable from the output table.
An example
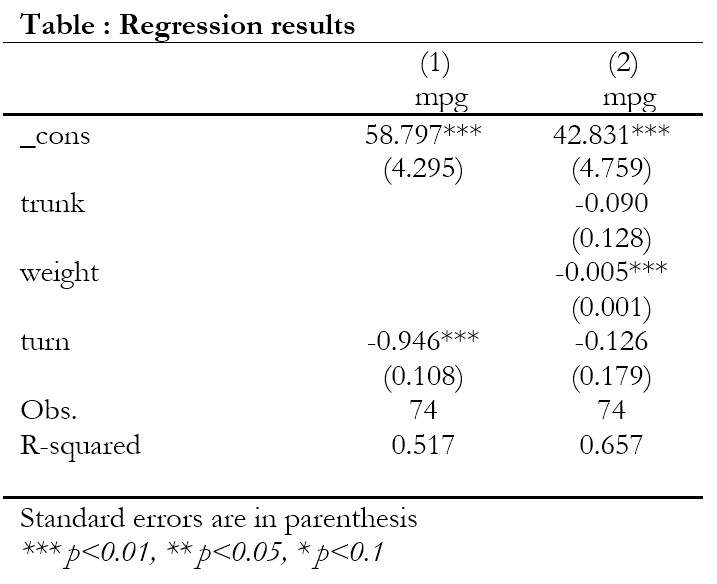
Let us use the auto dataset from the system folder and estimate two regressions. As with any other Stata command, we need to add asdoc to the beginning of the command line. We shall nest these regressions in one table, hence we need to use the option nest. Also, we shall use option replace in the first regression to replace any existing output file in the current directory. Let’s say we want the variables to appear in this order in the output file _cons trunk weight turn. Therefore, the variables are listed in this order inside the keep() option. The code and output file are shown below.
sysuse auto, clear
asdoc reg mpg turn, nest replace
asdoc reg mpg turn weight trunk, nest keep(_cons trunk weight turn)
2. Reporting only needed variables
Option keep is also used for reporting only needed variables, for example, we might not be interested in reporting coefficients of year or industry dummies. In such cases, we shall list the desired variable names inside the brackets of the keep() option. In the above example, if we wish to report only _cons trunk weight , we would just skip the variable turn from the keep option. Again, the variables will be listed in the order in which they are listed inside the keep option.
sysuse auto, clear
asdoc reg mpg turn, nest replace
asdoc reg mpg turn weight trunk, nest keep(_cons trunk weight)
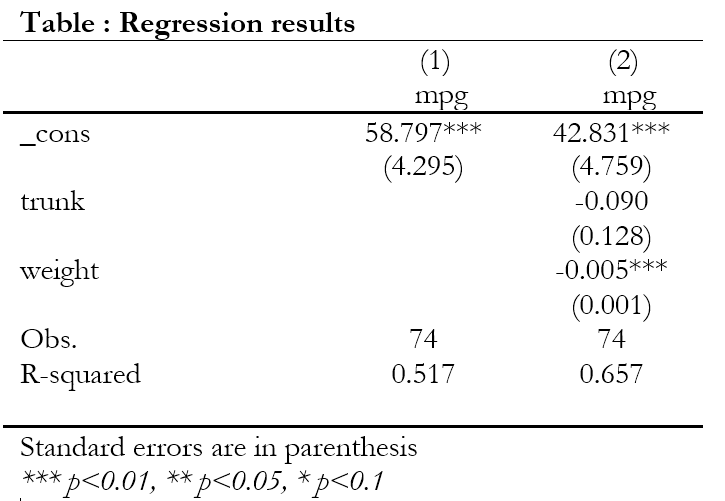
Off course, we could also have used option drop(turn) instead of option keep(_cons trunk weight) for dropping variable turn from the output table.
Two queries
1. Some time we are interested in F-Stat value and it’s P-Value. To identify the overall significance of model. Both asdoc and outreg do not report it in table. If you can guide please.
2. Can we add t-test or any other test for mean difference with in same regression table. For example, if we regress 5 portfolios and at last we are interested in testing mean difference of Port-1 and Port-5.
Fa:
For your first query, I would refer you to the help file of asdoc, Section 4. Regressions, subsection 4.10 option
stat(). You can use option stat() for reporting any statistic from thee()macro. These statistics are usually revealed by typingafter the regress command. The macro for F-statistic is
e(F). So if you wish to report it with asdoc, you can use optionstat(F). e.g,For your second query, I would refer you again to the help file of asdoc, Section 4, subsection 4.8, option
add(). You can use optionadd()to add up to three lines of additional text and statistics. This option adds text legends to the bottom cells of the nested regression table. The text legends should be added in pairs of two, each one separated by a comma. So to add mean of a variable to the regression table, see how I use this option. First, I create the mean withsumcommand, write it to a local named asmean1, and then add additional text and the local in theadd()option.Right now this option needs some additional tweaks as it deletes decimal points, therefore, I have written the above macro with zero decimal points. I shall work on it sometime in future.
Dear Mr. Shah,
First of all, I’d like to thank you for introducing the asdoc package to Stata. This is a great addition and I used it successfully many times. However, there seems to be a problem with asdoc when using a mixed model for analyzing panel data. For some reason, it gives me an error message.
command “
befristetwithin” is unrecognizedBefristetwithin is part of my analyses, which im trying to estimate as a random effect. I think there could be an issue with the highlighted part of my regression. Maybe asdoc does not know how to handle this part, since it involves some “unsual” signs. It would be great and i really appreciate it, if you could give me any advice on how to solve this issue.
my regression:
Kind Regards,
Paul Schumann
Dear Paul Schumann
Thanks for the feedback. I have changed asdoc and uploaded a new version to SSC. Please install it by
I hope it will solve the problem. Please do cite asdoc in your research.
In-text citation
Tables were created using asdoc, a Stata program written by Shah (2018).
Bibliography
Shah, A. (2018). ASDOC: Stata module to create high-quality tables in MS Word from Stata output. Statistical Software Components S458466, Boston College Department of Economics.
Hi Dr Shah
Can w replace tstat instead of standard errors while reporting our results in Stata?
I mean use “tstat in paranthesis” instead of “Standard errors are in parenthesis” ???????
Farah Zamir
The option
rep(t)can be used for reporting t-statistics when making a nested regression table.Dear Mr. Shah,
Thank you for your dedicated introduction of asdoc. Its user friendlyness and concise helpfiles make it a great addition to Stata.
I have a question regarding the significance stars. When using the “eform” option of cloglog, the significance stars seem to be reported incorrectly. I think that this is because the regression coefficients are exponentiated while the standard errors are not; hence the stars are reported over the wrong franction – but this is just a guess.
It would be great if you could have a look at this. Thank you very much.
Dear Bram Hogendoorn
Thanks for your kinds words and pointing out this bug. The problem occurs in cloglog regression when using option
eformandnesttogether. I shall rectify the error soon.Good day Mr Shah, thanks for the command.
I am experiencing problems with the
nestoption of the command.my code is:
and I receive the error:
func_nested_reg(): 3001 expected 29 arguments but received 30 : - function returned errorI am aware that you have responded to similar posts, however I followed your advice on reinstalling the command yet the error still persists. Is there something wrong with the code?
regards
Joshua
You can check the version of your asdoc, the current version is
If you have the same version, the please delete the installation file first and re-install asdoc. To put all the required codes lines in one place, please copy paste all of the following lines and paste in the Stata command window. Once done, then restart Stata.
Hi, I am having trouble showing the column name using the cname function in asdoc.
The resulting table does not have the cnames added. katrinacounty is a dummy variable with 0 signifying that counties are outside the impacted area and 1 denoting a FEMA Designated Area.
Try removing the add(citation) from the command and let me know if that causes the issue. I shall add an option of cite to generate the citation.
Can we customize the SEs text below the table? Like “Clustered Standard errors at county-level are in parentheses”. There are analyses that don’t use robust SEs but clustered
Such customization is easy in asdocx https://fintechprofessor.com/asdocx/
Hello Prof Shah, thank you for creating this really great stata command. I have one question. When I am exporting a nested regression, it is not showing the label of the reference category in an i. regression. Instead it displays ‘1bn’ or ‘2bn’ which is not clear to the reader or to me, what it refers to. The code I have used is below where I would like it to specify the label of the third category of occupation (occ_2), and the first categories of age, gender, sex etc. as the reference categories for the remainder. I’ve tried using rnames as you can see at the end of the replace, but it didn’t make any difference.
Your response is very welcom e
bys place: asdoc reg diff_contacts_ld ib3.occ_2 i.gender i.age_5 i.site i.ses_5, label nested abb(.) title(Determinants of Difference in contacts by Place Pre-Post Lockdown) save(tables/q4/reg_diff_by_place_nested_lbl) replace rnames(occupation gender age site ses)